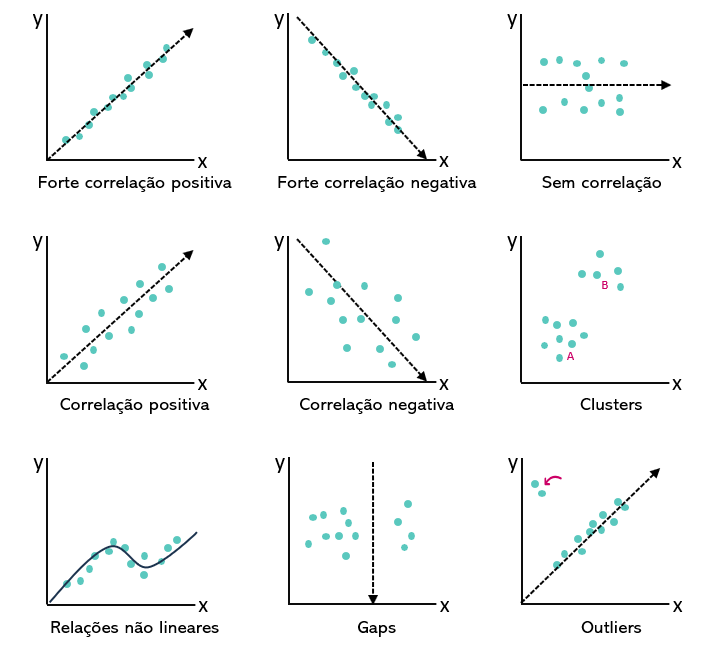
O gráfico de disperção é uma ferramenta estatística que organiza os dados visualmente permitindo compreender a relação entre duas variáveis quantitativas(numéricas). Quando obsevamos que ao aumentar o valor do eixo x aumentar também o valor do eixo y dizemos que ele possui uma correlação positiva, como poderemos observar mais abaixo.
A dispersão(distância de cada ponto da reta), nos mostra quantos os dados estão espalhados em relação uma média(reta no gráfico). As medidas de dispersão mais comuns utilizadas são a variância e desvio padrão. Quando os pontos estão muito espalhados em relação a reta, eles possuem desvio padrão e variância alta.
Figura - Grafico de disperção
Qual o objetivo
Auxiliar na demonstração e identificação de padrões como por exemplo correlação, clusters, outliers, relações lineares e não lineares, disperção da média entre outros.
Auxliar na análise do fenômeno durante a melhoria de processos.
De onde vem
Necessiade de uma ferramenta que forneça suporte visual com aparência simples e completa, que possa ser usado com variáveis dependentes ou independentes, que seja fácil de interpretar e possibilite comunicar os resultados com eficiência.
Conforme Korteling, Brouwer, and Toet (2018), o cerebro humano funciona de forma altamente associativa buscando por correlações e relações causais o tempo todo e essa característica confere ao ser humano uma capacidade inigualavel de reconhecer padrões regulares e ordenados e tendo dificuldade em lidar com aleatoriedade, imprevisibilidade e caos. Nestas situações, o gráfico de dispersão pode ser muito útil organizando e apresentados dados de uma forma que simplifica o trabalho para o cerebro humano.
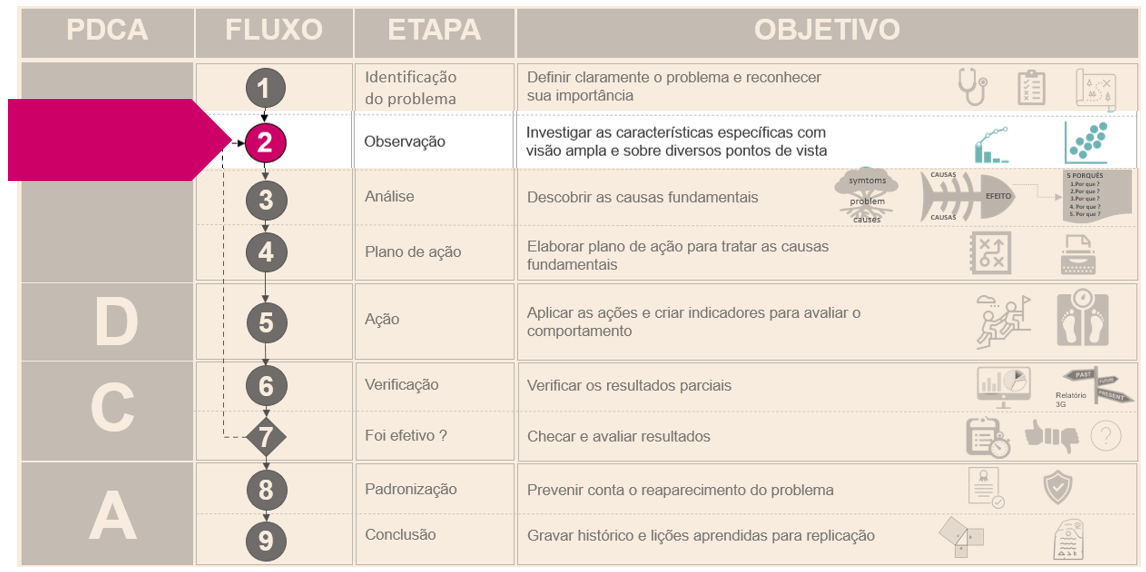
Figura - Etapa 2 do PDCA: Análise do fenômeno
Como fazer
O gráfico de disperção por sem simples é possível ser feito em planilhas e também em ferramentas de business intelligence ou ferramentas estatísticas como o R. Apresento aqui alguns modelos.
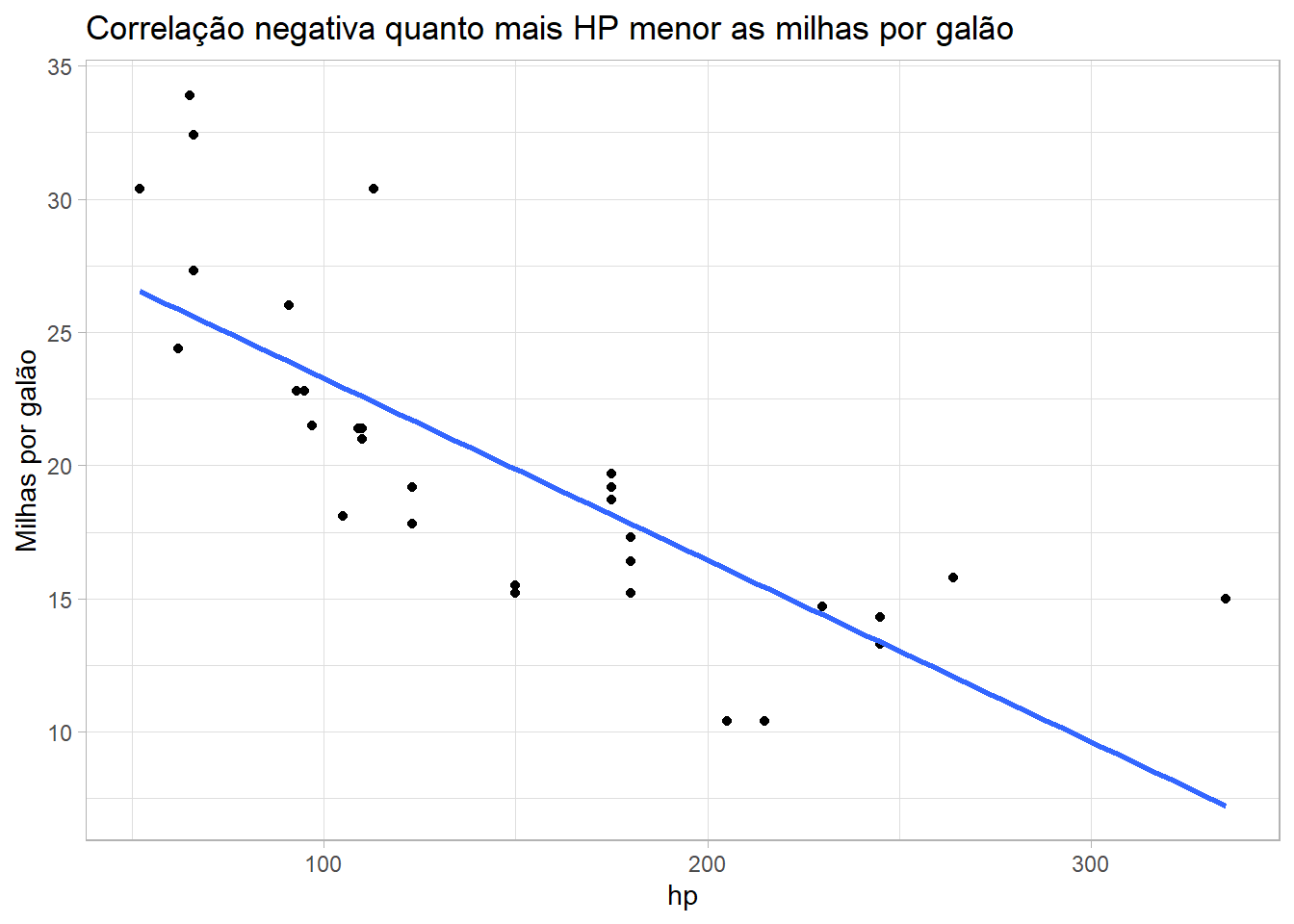
Neste exemplo temos um gráfico de correlação negativa ou seja, no eixo X tenos a variável HP e quanto mais HP menor será a milhagem por galão de combustível representada no eixo Y.
Será que quanto mais HP tiver o veículo menor será as milhas por galão que ele faz?
Code
library(tidyverse)library(modeldata)library(scales)library(ggpubr)mtcars |>ggplot(aes(x = hp, y = mpg))+geom_point()+geom_smooth(method ="lm", se =FALSE)+labs(title ="Correlação negativa quanto mais HP menor as milhas por galão",y ="Milhas por galão")+theme_light()
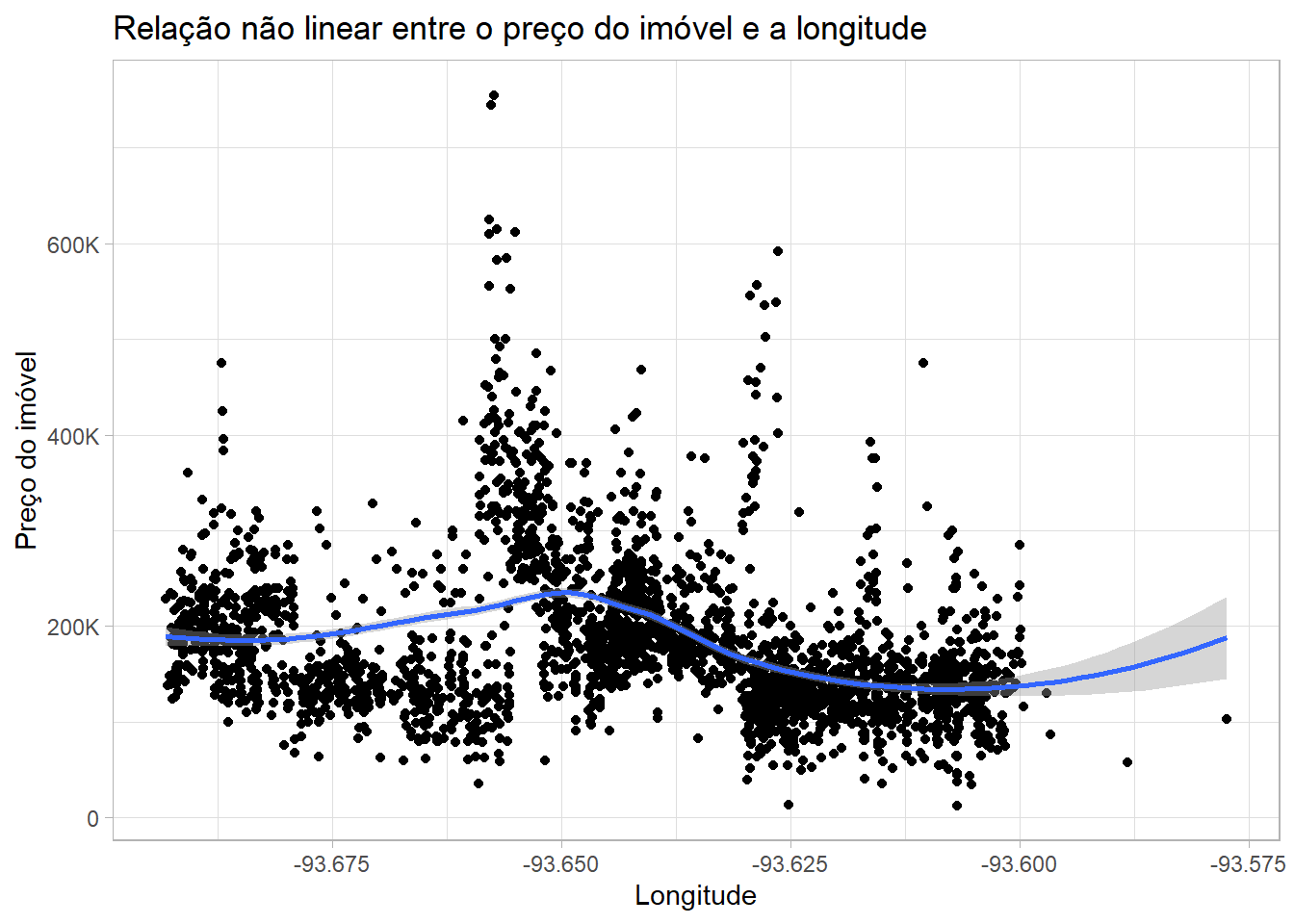
Será que a longitude tem correlação positiva com o preço dos imóveis?
Neste exemplo temos um gráfico que mostra uma relação não linear entre a localização e o preço, onde a variável longitude que é uma das medidas de posicionamento ou localização do imóvel está representado no eixo X enquanto a variável preço, está representada no eixo Y.
Code
ames |>ggplot(aes(x = Longitude, y = Sale_Price))+geom_point()+geom_smooth(method ="loess", formula = y ~ x)+scale_y_continuous(labels =label_number(scale_cut =cut_short_scale()))+labs(title ="Relação não linear entre o preço do imóvel e a longitude",y ="Preço do imóvel")+theme_light()
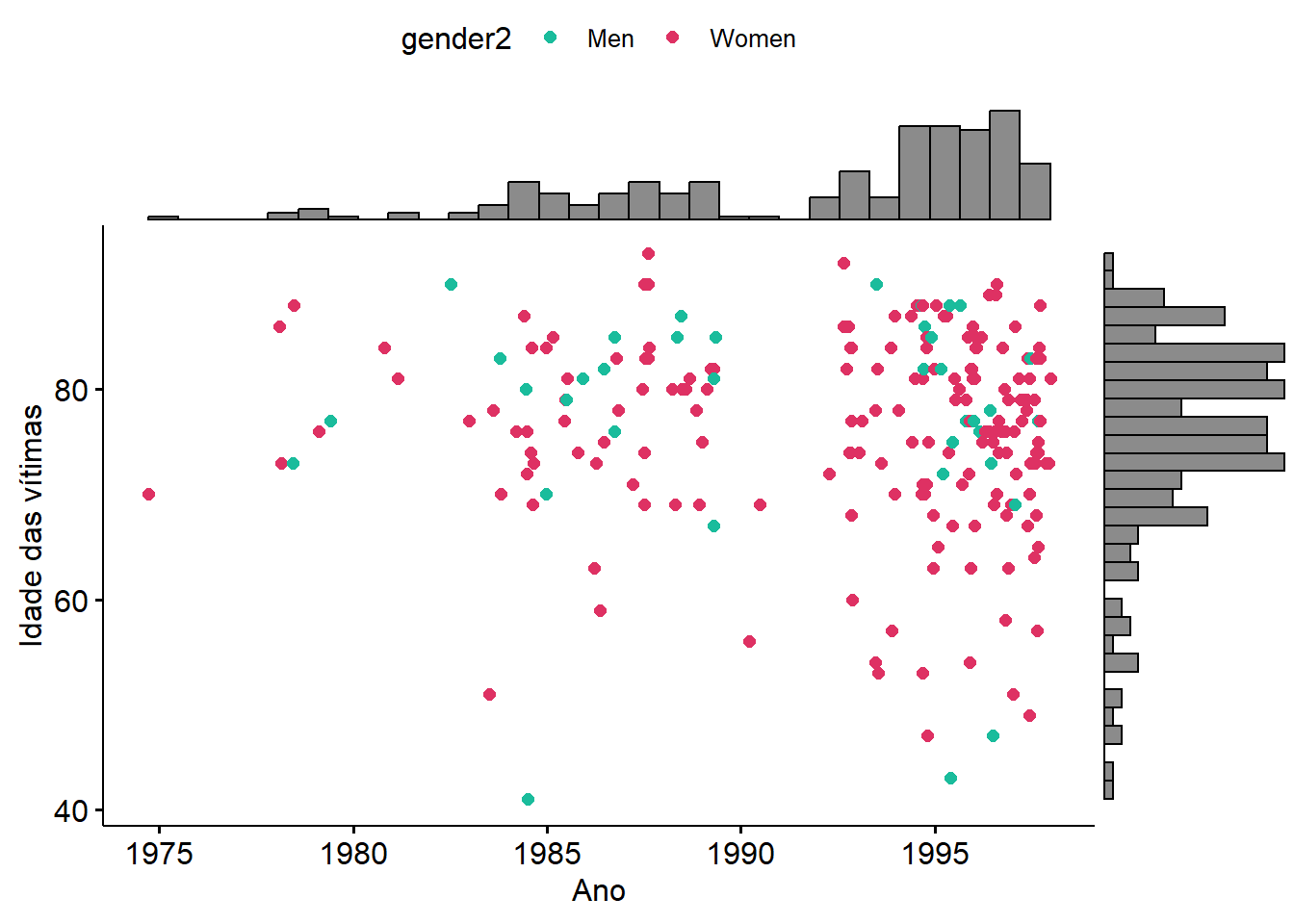
Exemplo de gráfico de dispersão elustrando o caso de Harold Shipman do livro The Art of Statistics
O gráfico de disperção(scatter-plot), nos mostra no eixo y a idade das 215 vítmas de um serial killer inglês chamado Harold Shipman que trabalhava como médico familiar. Note um gap entre os períodos de 1990 até 1992, com redução significativa das vítimas em sua maioria do sexo feminino. Nesse período, ele executava suas funções de forma intercalada com outros médicos da equipe o que tornava suas práticas suspeitas. Em seguida, ele proseguiu em sua atividade sozinho, e o número de vítimas acelerou até sua prisão. Os detalhes podem ser vistos em Spiegelhalter and Schlesinger (2022).
Code
library(tidyverse)library(ggpubr)data_crime <-read.csv("https://raw.githubusercontent.com/dspiegel29/ArtofStatistics/master/00-1-age-and-year-of-deathofharold-shipmans-victims/00-1-shipman-confirmed-victims-x.csv") %>% janitor::clean_names()#plot3 using ggpubr data_crime |>ggscatterhist(x ="fractional_death_year",y ="age",margin.plot ="histogram",color ="gender2",margin.ggtheme =theme_void(),palette =c("#1abc9c","#DE3163"),xlab ="Ano",ylab ="Idade das vítimas")
Pra onde vai
No ciclo PDCA o gráfico de dispersão é utilizado principalmente na investigação das características específicas com visão ampla e sobre diversos pontos de vista. Após esta estapa, a próxima é descobrir as causas fundamentais.
Para decisões intermediárias durante a melhoria de process dando suporte a intuições iniciais a respeito do fenômeno e servindo de guia para alocação de esforços para investigações posteriores.
Qual o resultado
Apresentar, analisar e comunicar dados de forma eficiente possibilitando a identificação de padrões nos dados e investigação de fenômenos sob diversos pontos de vista.
Facilidade na leitura e interpretação dos resultados melhorando a compreensão de todos em relação ao problema ou fenômeno.
Por ser uma ferramenta comum, possibilita a reprodutibilidade e uso em praticamente todas as áreas e lugares e por todos os tipos de profissionais que buscam melhorar seus processos.
Referências
Korteling, Johan E., Anne-Marie Brouwer, and Alexander Toet. 2018. “A Neural Network Framework for Cognitive Bias.”Frontiers in Psychology 9 (September). https://doi.org/10.3389/fpsyg.2018.01561.
Spiegelhalter, David, and George Schlesinger. 2022. A Arte Da Estatística: Como Aprender a Partir de Dados. 1ª edição. Zahar.